Benchmarking Vision Foundation Models for Domain-Generalizable Face Anti-Spoofing
Abstract
Face Anti-Spoofing (FAS) remains challenging due to the requirement for robust domain generalization across unseen environments. While recent trends leverage Vision-Language Models (VLMs) for semantic supervision, these multimodal approaches often demand prohibitive computational resources and exhibit high inference latency. Furthermore, their efficacy is inherently limited by the quality of the underlying visual features. This paper revisits the potential of vision-only foundation models to establish a highly efficient and robust baseline for FAS. We conduct a systematic benchmarking of 15 pre-trained models, such as supervised CNNs, supervised ViTs, and self-supervised ViTs, under severe cross-domain scenarios including the MICO and Limited Source Domains (LSD) protocols. Our comprehensive analysis reveals that self-supervised vision models, particularly DINOv2 with Registers, significantly suppress attention artifacts and capture critical, fine-grained spoofing cues. Combined with Face Anti-Spoofing Data Augmentation (FAS-Aug), Patch-wise Data Augmentation (PDA) and Attention-weighted Patch Loss (APL), our proposed vision-only baseline achieves state-of-the-art performance in the MICO protocol. This baseline outperforms existing methods under the data-constrained LSD protocol while maintaining superior computational efficiency. This work provides a definitive vision-only baseline for FAS, demonstrating that optimized self-supervised vision transformers can serve as a backbone for both vision-only and future multimodal FAS systems.
Overview

Figure 1. Overview of our comprehensive benchmarking framework and the proposed vision-only baseline. (A) We systematically categorize and evaluate 15 vision foundation models across three pre-training paradigms: Supervised CNNs, Supervised ViTs, and Self-Supervised & Multi-modal ViTs. (B) Based on benchmark insights, we construct an efficient baseline using DINOv2 with Registers, enhanced by FAS-Aug, PDA, and APL. (C) Evaluations under the MICO and LSD protocols demonstrate superior domain generalization.
We conduct a systematic benchmarking of 15 pre-trained models — supervised CNNs, supervised ViTs, and self-supervised ViTs — under severe cross-domain scenarios including the MICO and Limited Source Domains (LSD) protocols. Our comprehensive analysis reveals that self-supervised vision models, particularly DINOv2 with Registers, significantly suppress attention artifacts and capture critical, fine-grained spoofing cues. Combined with FAS-Aug, PDA, and APL, our proposed vision-only baseline achieves state-of-the-art performance among vision-only methods under the MICO protocol and outperforms existing methods under the data-constrained LSD protocol, while maintaining superior computational efficiency.
Vision Foundation Model Benchmark
To evaluate the inherent representation power of each backbone, FAS-Aug, PDA, and APL are disabled in this experiment. Self-supervised models generally outperform supervised counterparts, suggesting that self-supervised pre-training yields features with higher transferability for cross-domain FAS. Among self-supervised models, DINOv2 with Registers demonstrates the most robust and consistent domain generalization: while DINOv3 achieves the highest accuracy in specific scenarios (OMI→C and ICM→O), its performance suffers a significant drop in the challenging OCM→I protocol, whereas DINOv2 with Registers maintains high accuracy across all protocols. With the highest mean AUC of 96.25%, DINOv2 with Registers outperforms both DINOv3 (95.14%) and CLIP (95.41%), confirming its selection as the backbone for our baseline.
| Model | CIO→M ↑ | OMI→C ↑ | OCM→I ↑ | ICM→O ↑ | Avg. ↑ |
|---|---|---|---|---|---|
| ConvNeXt | 95.95 | 95.78 | 84.87 | 84.26 | 90.22 |
| ViT-B | 91.81 | 96.82 | 95.30 | 91.96 | 93.97 |
| EfficientFormer | 93.67 | 93.55 | 81.61 | 84.55 | 88.35 |
| MobileViT | 96.73 | 94.99 | 82.92 | 90.80 | 91.36 |
| DeiT-tiny | 90.10 | 69.40 | 68.09 | 78.63 | 76.56 |
| DeiT-base | 88.82 | 83.21 | 77.36 | 75.17 | 81.14 |
| Swin Transformer | 97.20 | 98.78 | 92.44 | 93.42 | 95.46 |
| Data2vec | 88.82 | 95.13 | 77.36 | 93.47 | 88.70 |
| BEiT | 97.25 | 95.80 | 82.24 | 88.89 | 91.05 |
| MAE | 94.41 | 90.00 | 84.06 | 91.84 | 90.08 |
| CLIP | 98.52 | 94.95 | 92.20 | 95.95 | 95.41 |
| DINO | 97.01 | 97.00 | 91.12 | 94.80 | 94.98 |
| DINOv2 | 96.90 | 98.02 | 91.05 | 96.23 | 95.55 |
| DINOv2 with Registers ★ | 97.47 | 98.30 | 93.83 | 95.38 | 96.25 |
| DINOv3 | 95.42 | 98.80 | 89.21 | 97.13 | 95.14 |
▮ Supervised CNNs ▮ Supervised ViTs ▮ Self-Supervised & Multi-modal ViTs Bold: best, underline: 2nd best
Proposed Vision-Only Baseline
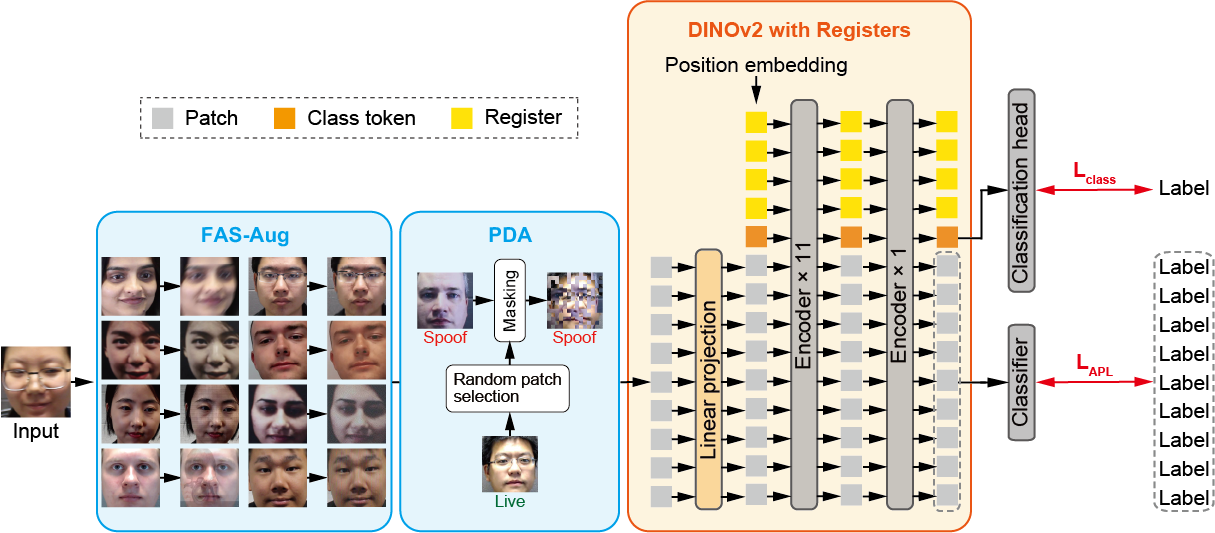
Figure 2. Overview of the proposed vision-only baseline. During training, input images are augmented by FAS-Aug and PDA to simulate diverse spoofing artifacts and enforce robust local representations. The processed images are fed into the DINOv2 with Registers backbone and optimized via a dual-level supervision strategy: a global classification loss (Lclass) from the class token, and a local Attention-Weighted Patch Loss (LAPL) applied to patch tokens.
The baseline fine-tunes DINOv2 ViT-B/14 with Registers end-to-end. Register tokens — learnable tokens appended to the input sequence — mitigate the attention spike phenomenon in standard ViTs, where anomalously high attention concentrates on irrelevant background regions. This stabilizes the attention mechanism, yielding smoother attention maps that accurately capture the minute visual cues essential for spoof detection.
Two complementary augmentations are applied during training only. FAS-Aug simulates eight types of spoofing artifacts (photography noise, print attacks, and display attacks), randomly applied to each input. PDA replaces patches in a spoof image with corresponding live patches (P=0.5), increasing task difficulty and compelling the model to learn discriminative local representations.
The network is optimized with a dual-level loss Ltotal = Lclass + LAPL. Lclass is the binary classification loss on the class token. LAPL (Attention-Weighted Patch Loss) applies a patch-wise binary classification loss, where each patch prediction is weighted by the class-token attention map of the final encoder block; L2-constrained Softmax is used to ensure balanced learning between Live and Spoof classes.
Experimental Results
MICO Protocol (Cross-Dataset Evaluation)
Cross-dataset evaluation under the MICO leave-one-out protocol using MSU MFSD (M), IDIAP Replay Attack (I), CASIA-FASD (C), and OULU-NPU (O). Our baseline shows overall competitive performance across most settings. While it does not uniformly dominate every protocol, it exceeds existing vision-only methods on OMI→C and ICM→O, and achieves the highest average AUC (97.66%) among all vision-only methods. Compared to VLM-based methods (FLIP, CFPL, I-FAS), the gap is substantially narrowed — e.g., 98.92% vs. 99.99% on OMI→C — without relying on large-scale language models. Bold/underline: best/2nd-best among vision-only methods; VLM-based methods shown for reference.
| Method | CIO→M | OMI→C | OCM→I | ICM→O | Avg. | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| HTER↓ | AUC↑ | HTER↓ | AUC↑ | HTER↓ | AUC↑ | HTER↓ | AUC↑ | HTER↓ | AUC↑ | |
| DRDG | 12.43 | 95.81 | 19.05 | 88.79 | 15.56 | 91.79 | 15.63 | 91.75 | 15.67 | 92.04 |
| ANRL | 10.83 | 96.75 | 17.83 | 89.26 | 16.03 | 91.04 | 15.67 | 91.90 | 15.09 | 92.24 |
| SSDG-R | 7.38 | 97.17 | 10.44 | 95.94 | 11.71 | 96.59 | 15.61 | 91.54 | 11.29 | 95.31 |
| SSAN-R | 6.67 | 98.75 | 10.00 | 96.67 | 8.88 | 96.79 | 13.72 | 93.63 | 9.82 | 96.46 |
| PatchNet | 7.10 | 98.46 | 11.33 | 94.58 | 13.40 | 95.67 | 11.82 | 95.07 | 10.91 | 95.95 |
| TransFAS | 7.08 | 96.69 | 9.81 | 96.13 | 10.12 | 95.53 | 15.53 | 91.10 | 10.64 | 94.86 |
| DiVT-M | 2.86 | 99.14 | 8.67 | 96.92 | 3.71 | 99.29 | 13.06 | 94.04 | 7.08 | 97.35 |
| SA-FAS | 5.95 | 96.55 | 8.78 | 95.37 | 6.58 | 97.54 | 10.00 | 96.23 | 7.83 | 96.42 |
| IADG | 5.41 | 98.19 | 8.70 | 96.44 | 10.62 | 94.50 | 8.86 | 97.14 | 8.40 | 96.57 |
| GAC-FAS | 5.00 | 97.56 | 8.20 | 95.16 | 4.29 | 98.87 | 8.60 | 97.16 | 6.52 | 97.19 |
| Li | 12.92 | 94.33 | 9.26 | 96.98 | 10.87 | 95.46 | 15.13 | 91.43 | 12.05 | 94.55 |
| DiffFAS-V | 2.86 | 98.41 | 10.11 | 96.32 | 6.36 | 97.89 | 8.11 | 97.27 | 6.86 | 97.47 |
| ★ Ours (Baseline) | 8.86 | 96.95 | 4.49 | 98.92 | 9.81 | 96.70 | 7.35 | 98.07 | 7.63 | 97.66 |
| VLM-based methods (for reference) | ||||||||||
| FLIP | 4.95 | 98.11 | 0.54 | 99.98 | 4.25 | 99.07 | 2.31 | 99.63 | 3.01 | 99.20 |
| CFPL | 1.43 | 99.28 | 2.56 | 99.10 | 5.43 | 98.41 | 2.50 | 99.42 | 2.98 | 99.05 |
| I-FAS | 0.32 | 99.88 | 0.04 | 99.99 | 3.22 | 98.48 | 1.74 | 99.66 | 1.33 | 99.50 |
Limited Source Domains (LSD) Protocol
The LSD setting uses only two source datasets (MSU MFSD + IDIAP Replay Attack) for training, testing generalization from severely restricted domain diversity. While prior vision-only methods exhibit a severe performance drop under this setting, our approach maintains exceptional accuracy and surpasses all previous works — e.g., HTER 8.29% and AUC 97.10% on MI→C. This result strongly validates the effectiveness of our vision-only baseline in capturing domain-invariant cues, a key property for resource-constrained deployment.
| Method | MI→C | MI→O | ||
|---|---|---|---|---|
| HTER↓ | AUC↑ | HTER↓ | AUC↑ | |
| DRDG | 31.28 | 71.50 | 33.35 | 69.14 |
| ANRL | 31.06 | 72.12 | 30.73 | 74.10 |
| SSDG-M | 31.89 | 71.29 | 36.01 | 66.88 |
| SSAN-R | 30.00 | 76.20 | 29.44 | 76.62 |
| DiVT-M | 20.11 | 86.71 | 23.61 | 85.73 |
| IADG | 24.07 | 85.13 | 18.47 | 90.49 |
| GAC-FAS | 16.91 | 88.12 | 17.88 | 89.67 |
| FAS-Aug | 16.89 | 90.06 | 15.10 | 92.69 |
| DiffFAS-V | 15.06 | 92.83 | 16.19 | 92.62 |
| ★ Ours (Baseline) | 8.29 | 97.10 | 12.11 | 95.36 |
Computational Efficiency
Our DINOv2-based baseline adopts a purely vision-based architecture without any language model, achieving competitive cross-domain generalization with only 87M total parameters — less than 3% of I-FAS (~3.1B) and roughly 55% of CFPL (~157M). By relying solely on self-supervised visual representations, our baseline avoids the architectural complexity and computational burden of multimodal large language models, demonstrating that effective FAS generalization does not necessitate a VLM-based design.
| Method | Trainable Params [M] | Total Params [M] |
|---|---|---|
| CFPL | 94 | 157 |
| FLIP | 170 | 170 |
| I-FAS | 104 | 3,100 |
| ★ Ours (Baseline) | 87 | 87 |
BibTeX
@article{Feng_ICCVW_2025,
author = "Feng, M. and Gallin-Martel P. and Ito, K. and Aoki, T.",
title = "Benchmarking Vision Foundation Models for Domain-Generalizable Face Anti-Spoofing",
journal = "Proc. IEEE Conf. Computer Vision and Pattern Recognition Workshops",
year = "2026",
pages = "",
month = jun
}